Phuc Ngo, Phillip Isola
Recent works in multimodality systems have enabled image gener-
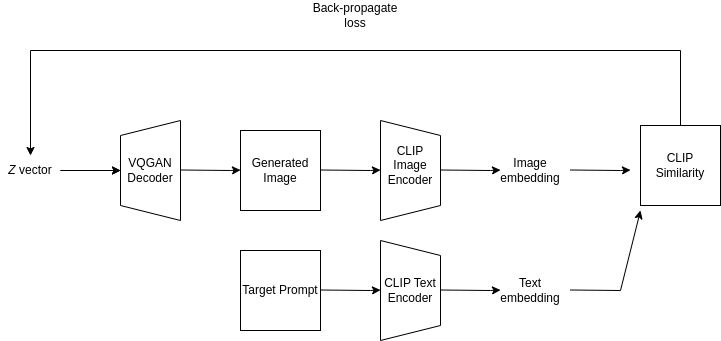
ations with instruction from another domain. Specifically, Contrastive Language-Image Pre-training (CLIP) allows multiple downstream tasks such as image synthesis, 3D object generation, and style transfer using text. However, the audio-image generation has not been much explored. In this work, we introduce Style-Wav, an algorithm that is adapted from StyleCLIP. Instead of using text guidance as in StyleCLIP, StyleWav uses audio representation from Wav2CLIP to guide the generated image using StyleGAN. We use synthesized images as a concrete benchmark for the transferred knowledge from the distillation process from
CLIP to the audio domain. For further application, the model’s code is public at:https://github.com/Jerry2001/StyleWav.