Probing for Auditory Representations in Language Models
|
|
|
|
|
|
|
|
Abstract
This work explores whether language models encode meaningfully grounded representations of sounds of objects. We learn a linear probe that retrieves the correct text representation of an object given a snippet of audio related to that object, where the sound representation is given by a pretrained audio model. This probe is trained via a contrastive loss that pushes the language representations and sound representations of an object to be close to one another. After training, the probe is tested on its ability to generalize to objects that were not seen during training. Across different language models and audio models, we find that the probe generalization is above chance in many cases, indicating that despite being trained only on raw text, language models encode grounded knowledge of sounds for some objects.
Methodology
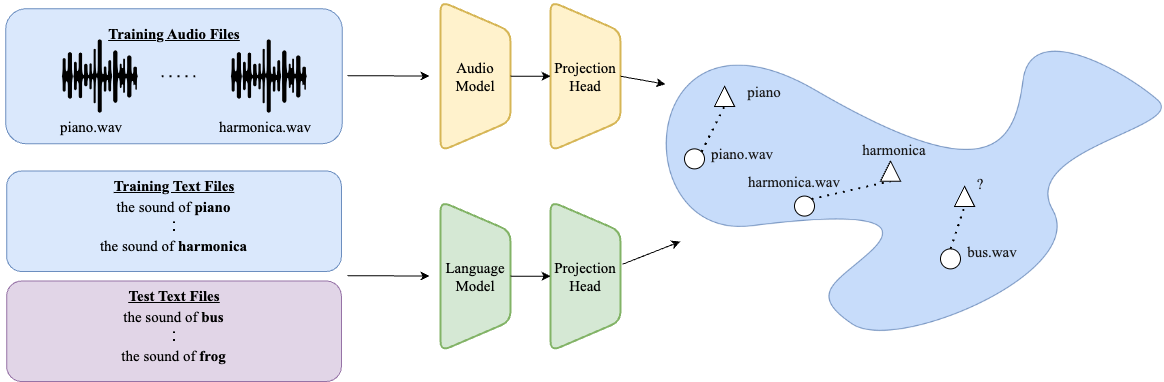
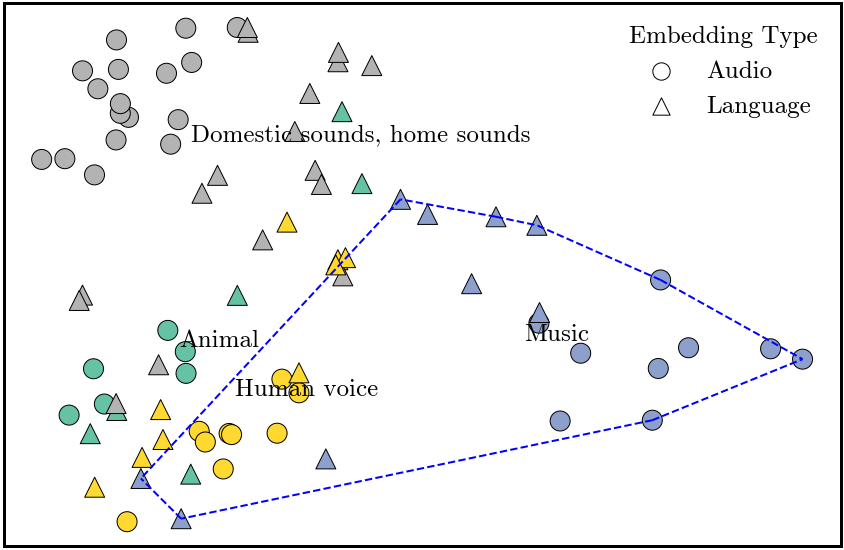
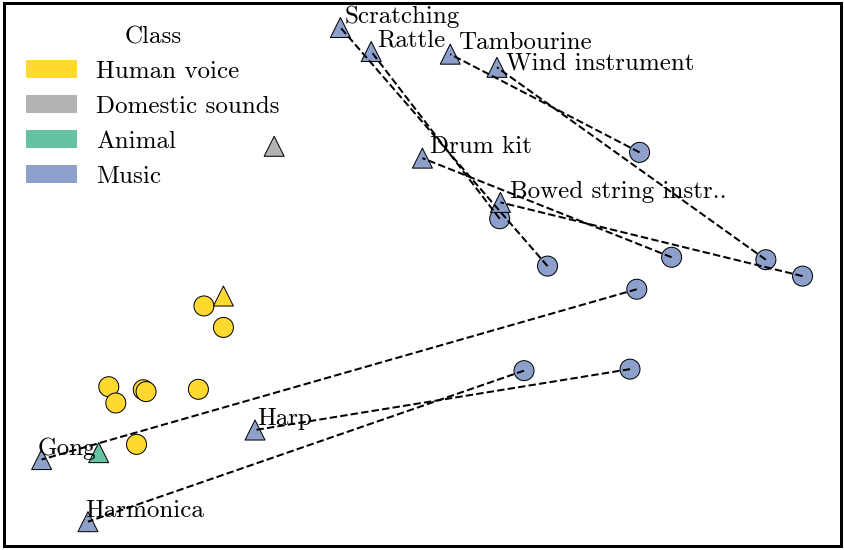
We randomly split a set of classes into mutually exclusive train/test sets. On the training set (blue), we use a contrastive loss to learn linear transformations (i.e., projection heads) of the sound and language representations such that a language representation of a class is close in cosine distance to the sound representation of the same class. After training, we apply the learned probe on audio snippets of classes from the test set, and retrieve the most similar text representation (from classes in both the train and test sets). We then test whether the retrieved class corresponds to the actual class.
Main Results
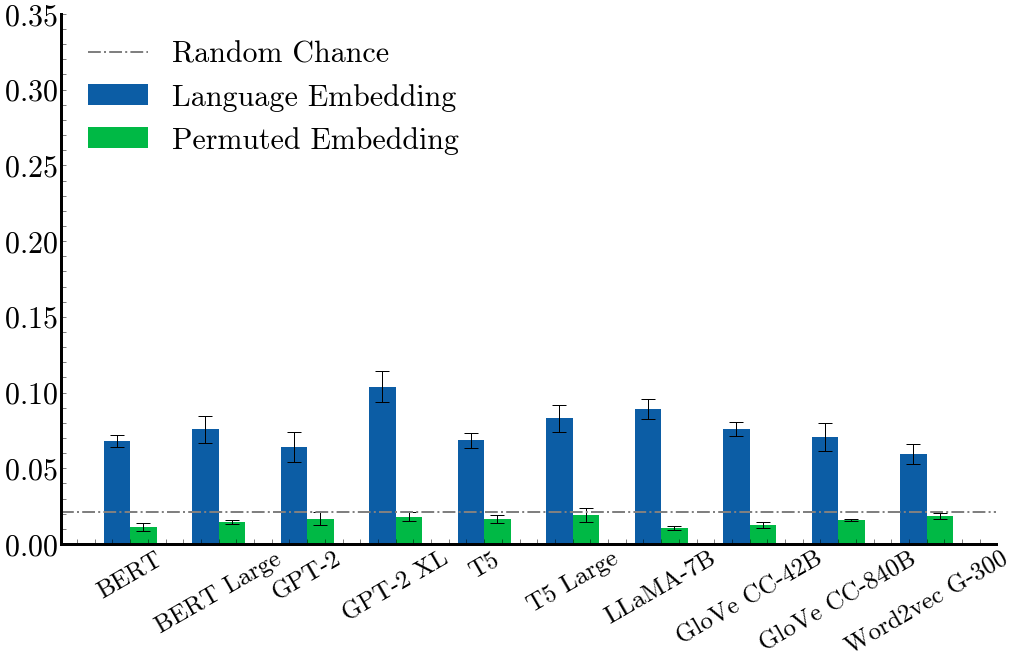
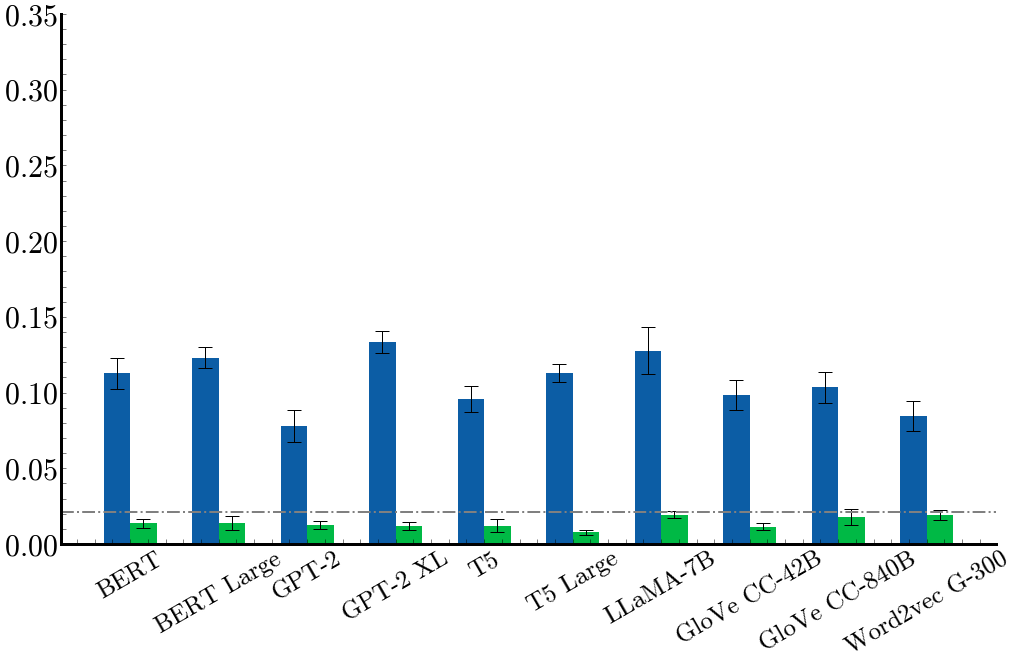
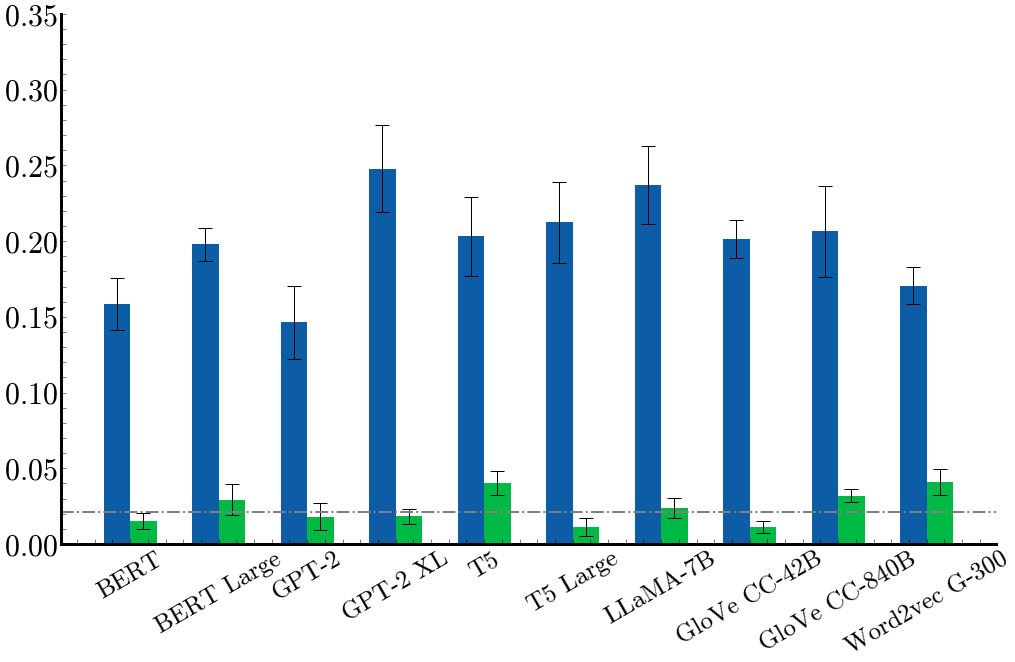
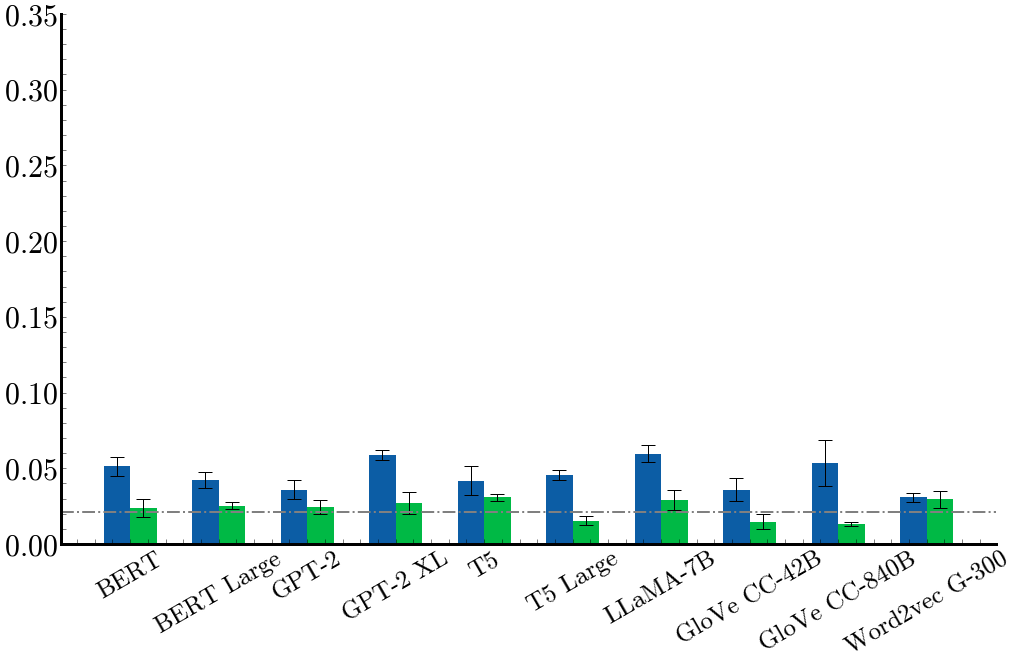
Our main results measure the linear probe accuracy@3 performance for the different language/sound representation combinations. Green bars show the accuracy of the permuted embedding control task, where the text representations are randomly permuted. Error bars show standard error of the mean across 5 runs. Dotted line shows random chance performance, which is 2.08%. We can see that most language models perform well above chance.
Acknowledgments
This study was partially supported by funds from the MIT-IBM Watson AI Lab.
Bibtex
@article{ngo_what_2024,
title={What Do Language Models Hear? Probing for Auditory Representations in Language Models},
journal={arXiv:2402.16998}
author={Jerry Ngo, Yoon Kim},
year={2024}
}